As the demand for on-device artificial intelligence rises, Google is taking significant strides with its AI Edge Portal, evolving its capabilities to meet the increasing complexity of deploying large language models (LLMs) on smartphones. The latest enhancements focus on delivering essential benchmarking and debugging tools that address the performance bottlenecks that developers face in this crowded ecosystem.
Contextualizing the Challenge in Edge AI Deployments
Deploying generative AI efficiently on edge devices has historically been a daunting task for developers. With a multitude of accelerators, operating systems, and hardware configurations, optimizing for each scenario often involves tedious, manual testing across a limited number of devices. Google’s AI Edge Portal seeks to dismantle this bottleneck by providing a platform where developers can perform automated tests across more than 120 representative Android devices. This extensive testing not only reveals insights on performance and latency but fundamentally aims to enhance user experience in apps that leverage LLMs.
New Benchmarking Capabilities: A Deeper Dive
The recent introduction of automated benchmarking tools in the Google AI Edge Portal positions developers to gauge their LLM's performance under real-world conditions. Key metrics such as initialization time, prefill speed, decode speed, and peak memory usage are now quantifiable across a diverse array of Android devices. For example, initialization time—critical in determining how long an app may seem unresponsive—can make or break user interaction. If your model uses excessive memory during startup, it could crash, leading to frustrated users. The AI Edge Portal allows developers to simulate these scenarios and gather actionable insights before deployment.
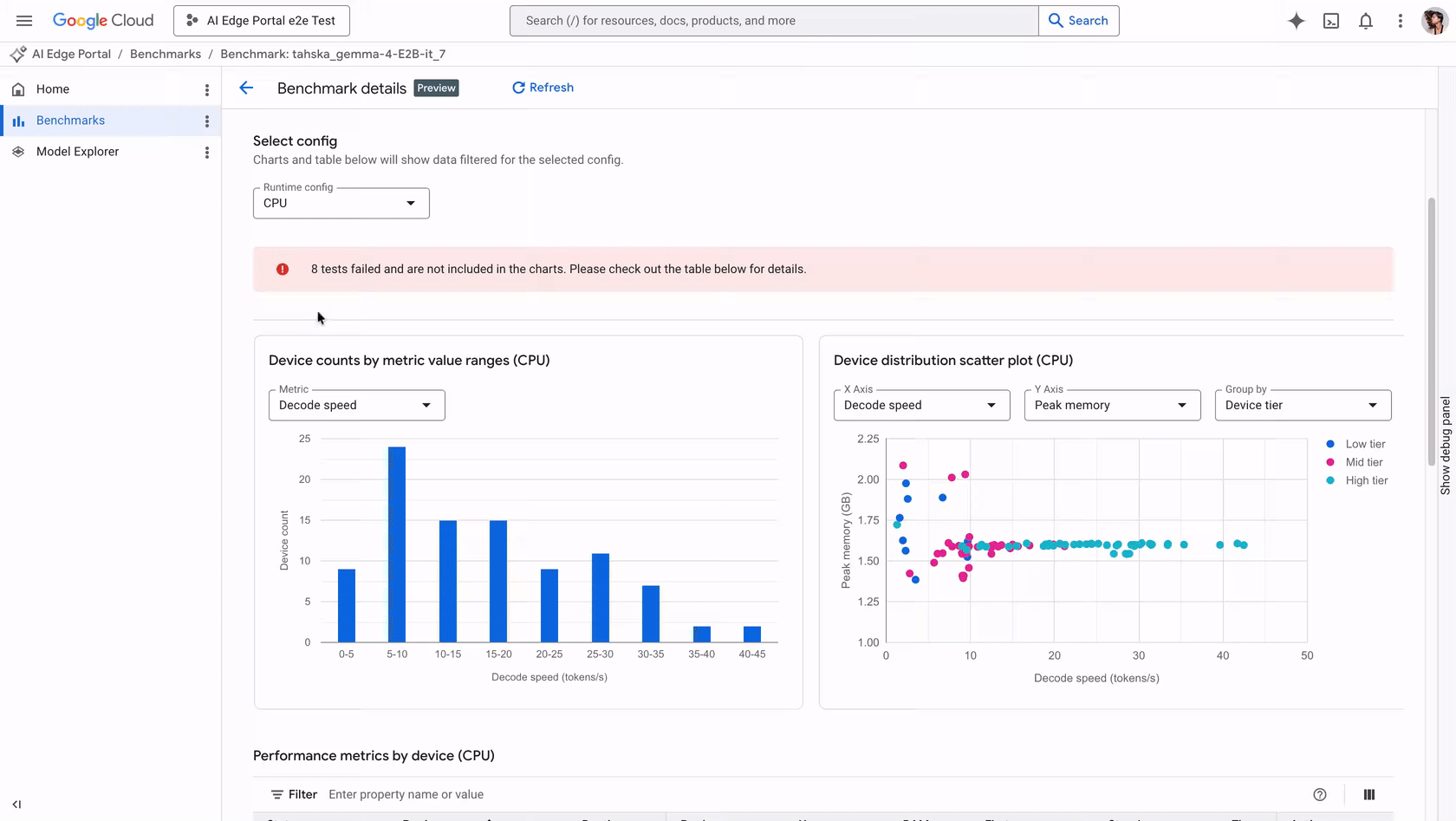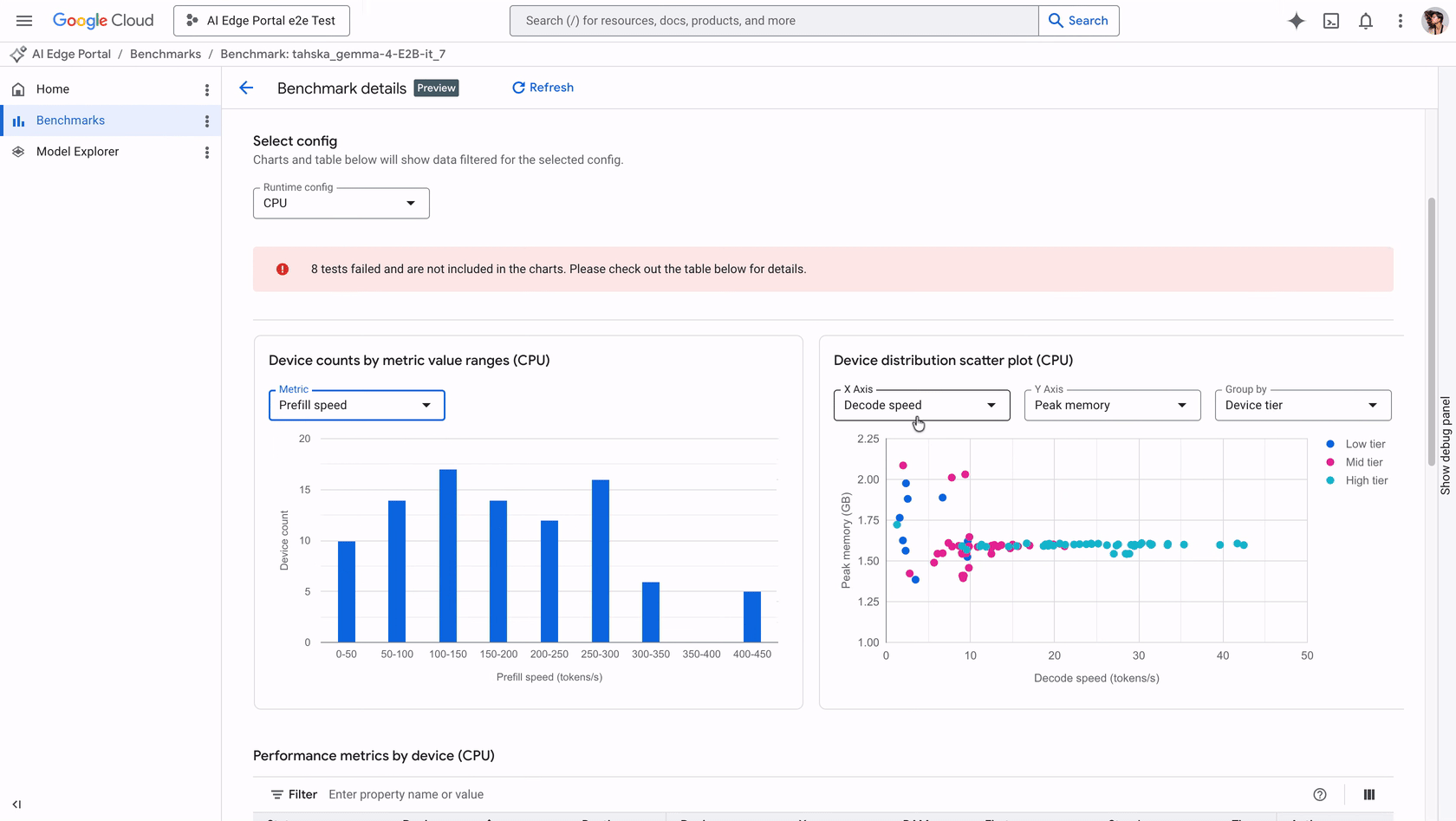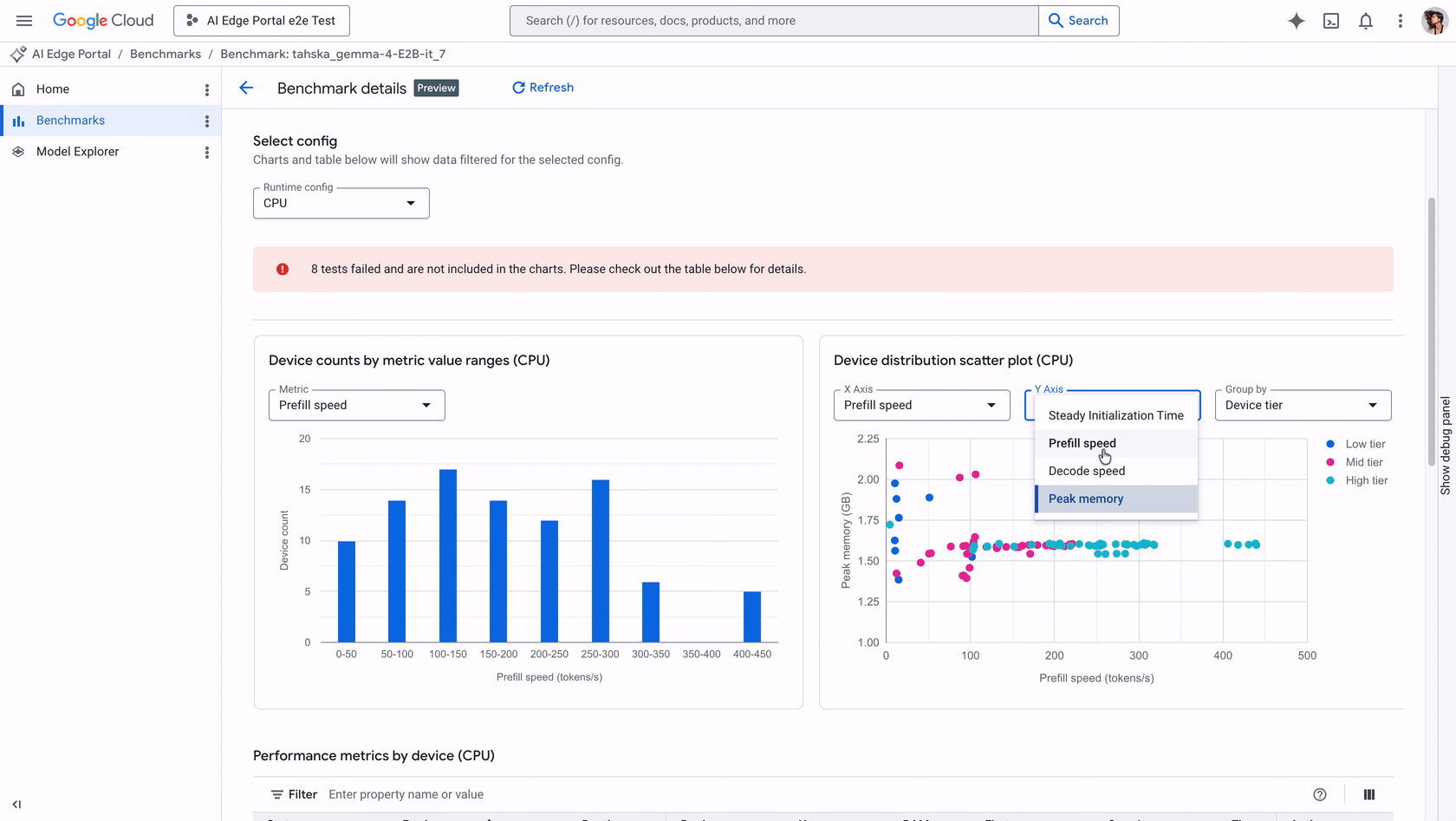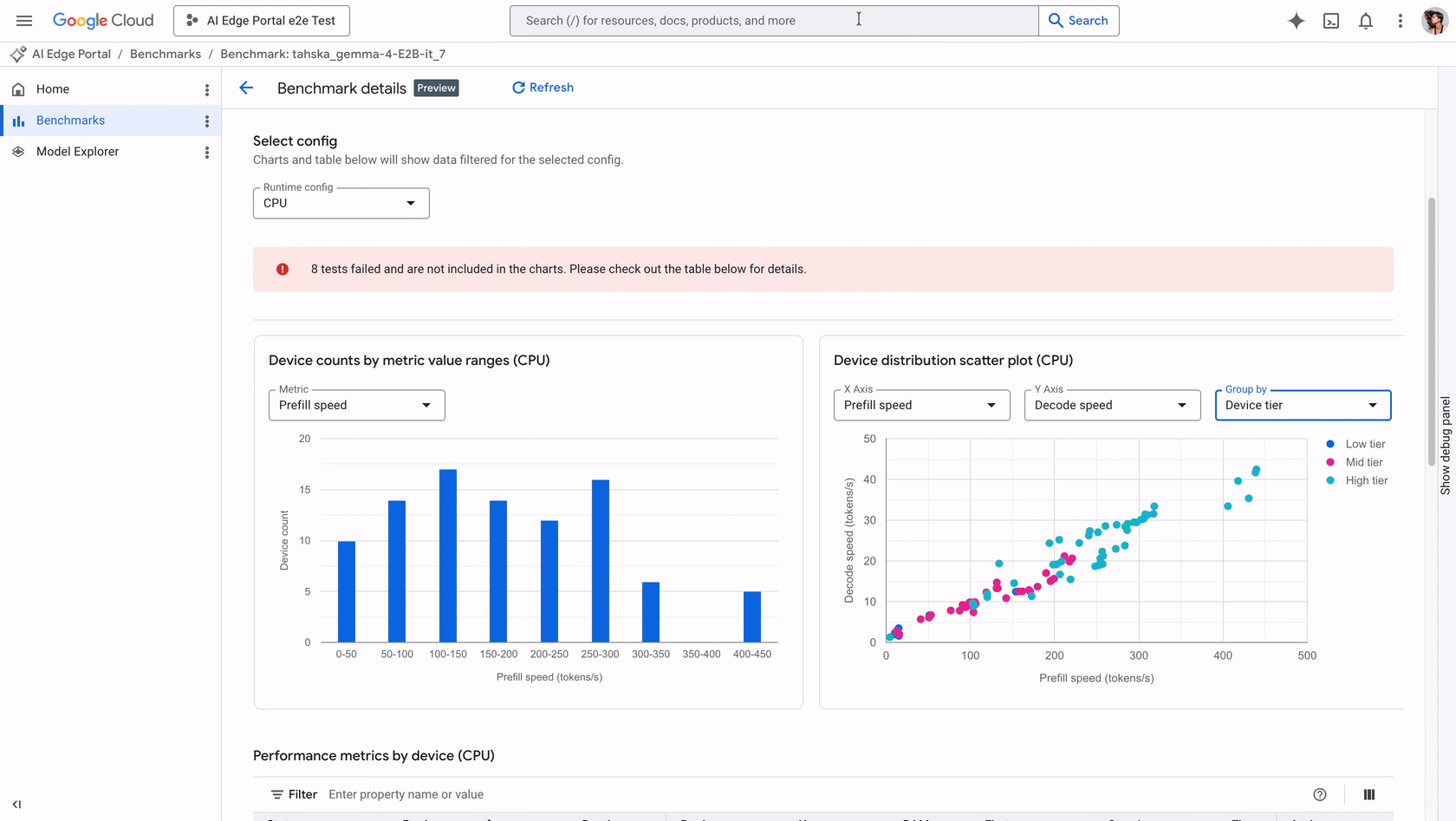
Customers can benchmark GenAI models on over 120 Android devices, viewing metrics including initialization time, prefill speed, decode speed, and peak memory usage.
Understanding the performance nuances of an LLM is now more tangible. For instance, prefill speed measures the time taken to process prompt tokens, a metric that dictates the latency perceived by the end user. Meanwhile, monitoring peak memory usage is essential to prevent crashes on memory-constrained devices, highlighting the need for optimized models that can fulfill user expectations without overextending hardware capabilities.
Advancements in Debugging: The Model Explorer
Benchmarking is only as good as the actions taken based on its results. To streamline the debugging process, Google introduces the Model Explorer, which allows developers to visualize model graphs and pinpoint inefficiencies in their architectures. As LLMs can have thousands of nodes, navigating performance issues can often feel like finding a needle in a haystack. The Model Explorer simplifies this by offering side-by-side comparisons of models, enabling users to identify and address specific layers that may hinder performance.
This tool shines particularly when it comes to identifying quantization challenges—where a model’s performance may be compromised during optimization efforts. By prioritizing operations based on error metrics, developers can make more informed decisions to balance model size and output quality. Enhanced visibility into hardware compatibility further enhances the potential for efficient adjustments prior to deployment.
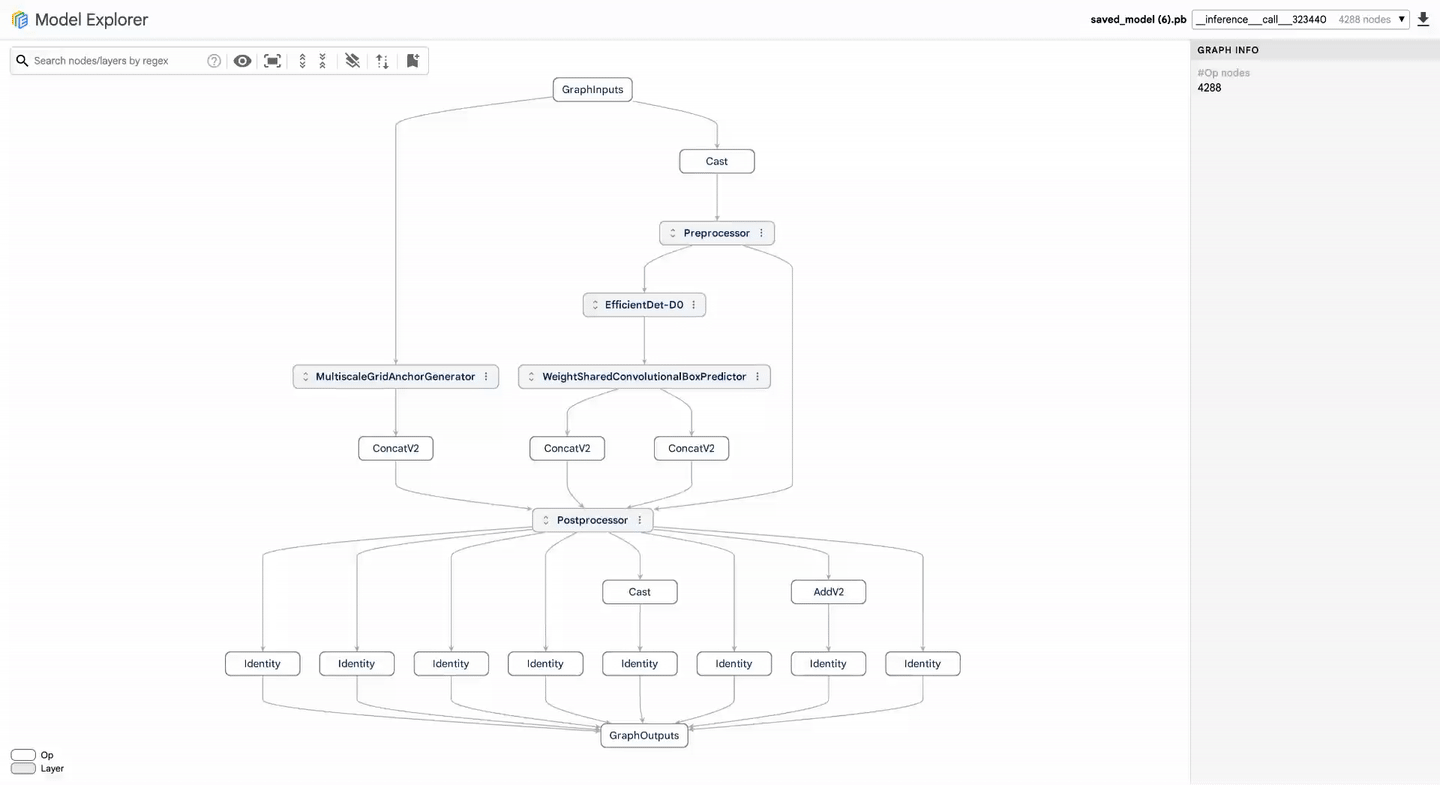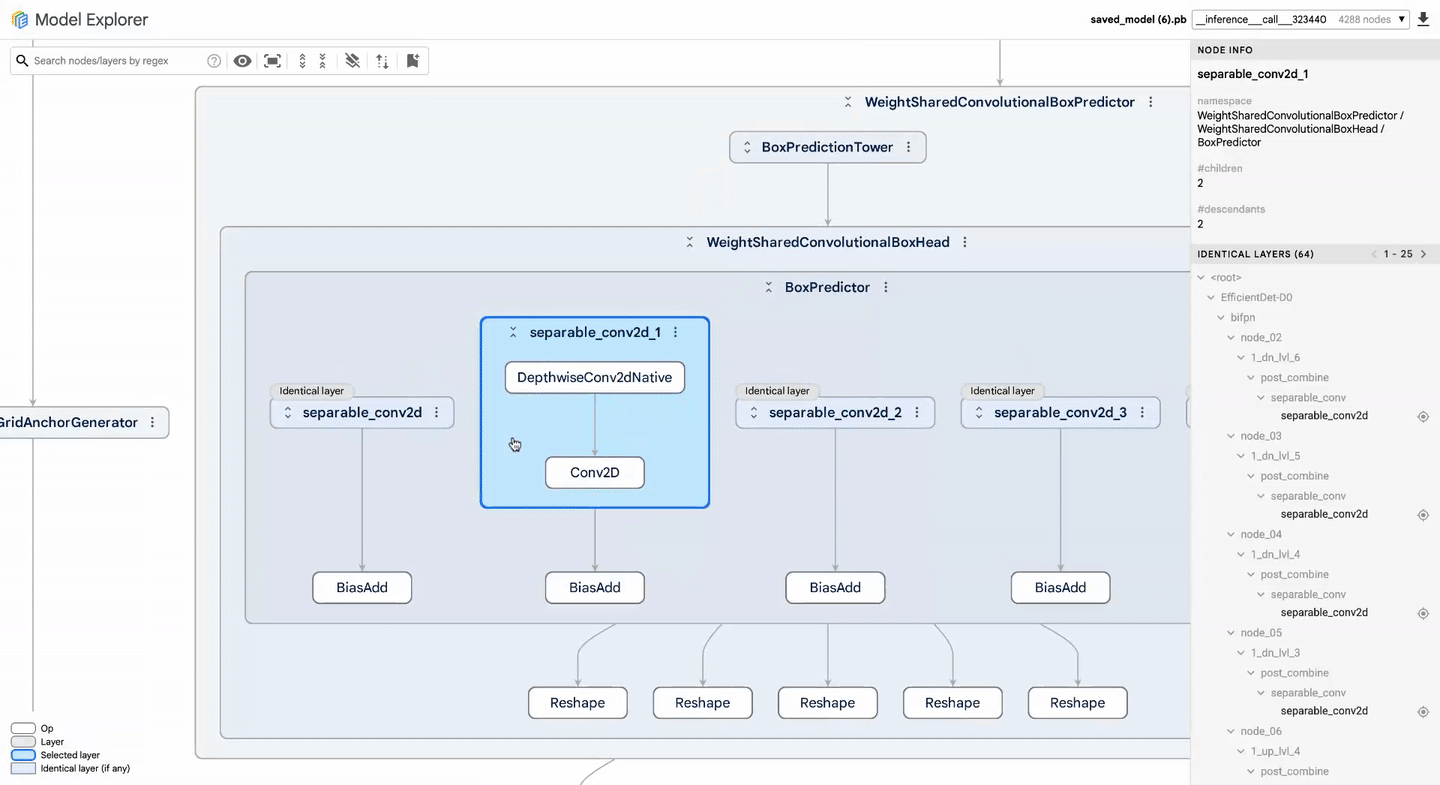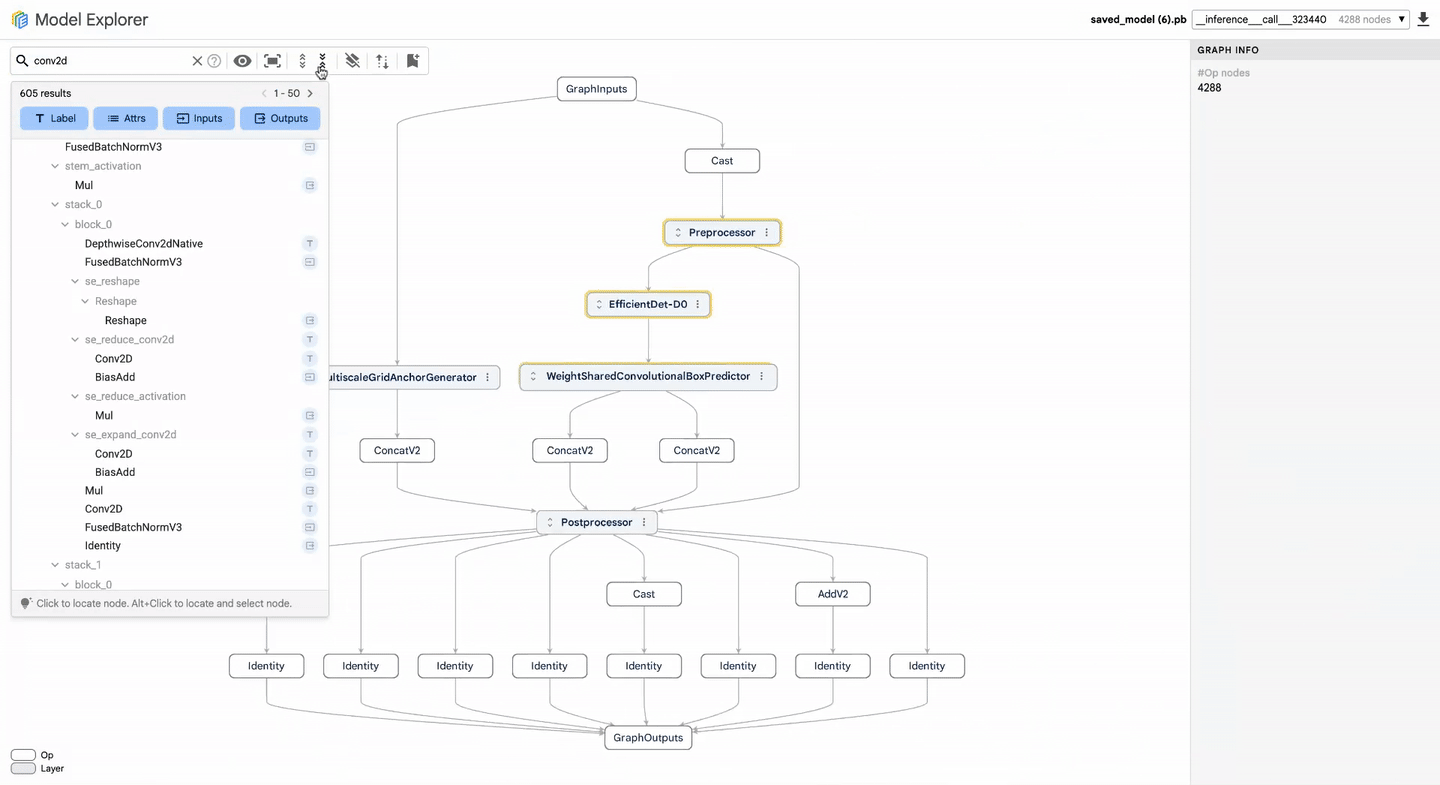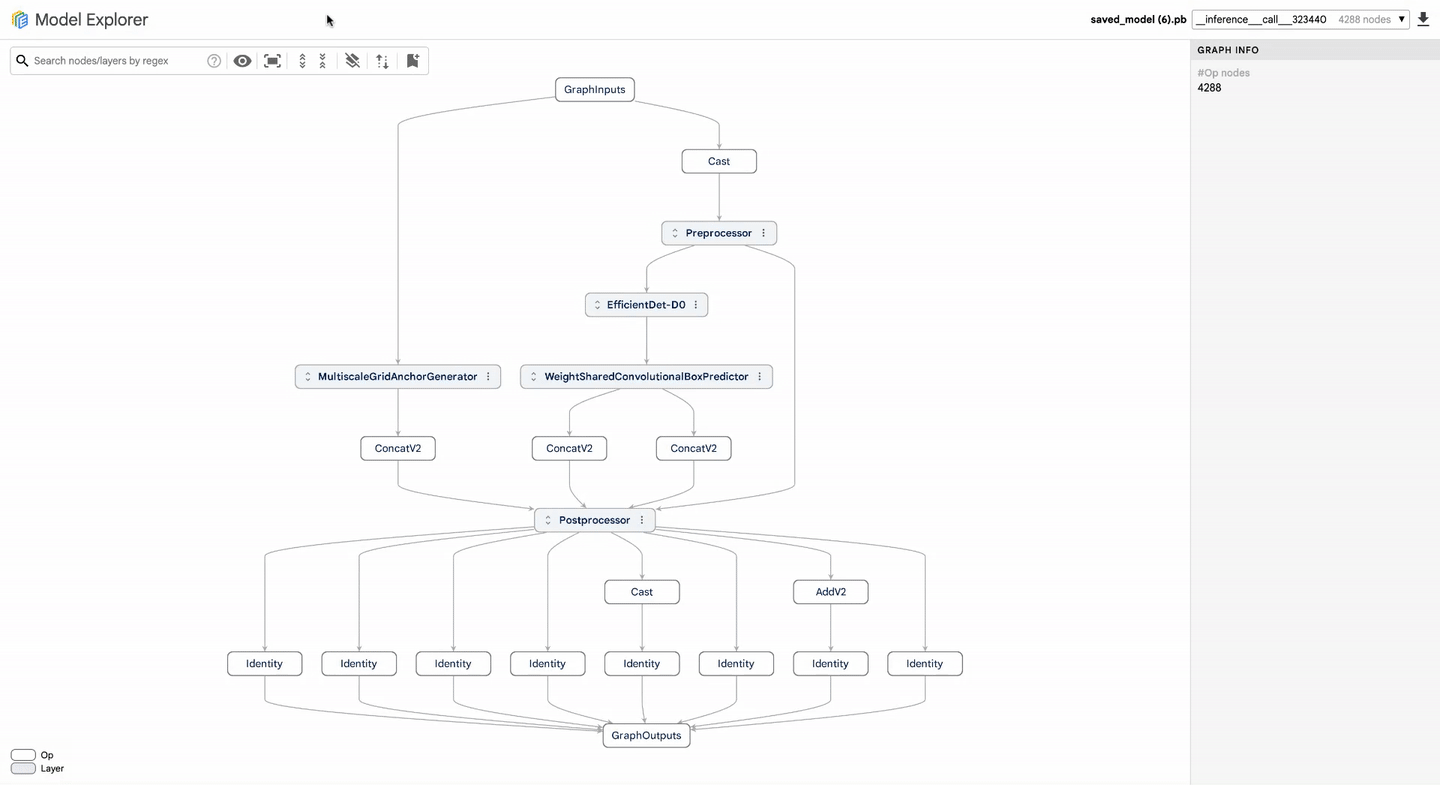
With Model Explorer, you can view model graphs, search for specific layers, and compare models side-by-side to debug performance.
Implementing the New Features
The introduction of these tools leads directly into a transformative opportunity for developers. The shift toward on-device LLM capabilities necessitates that they not only measure performance metrics but also engage in actively debugging their models in response to findings. The ability to readily assess which devices can successfully host a model opens doors for broader LLM implementations across a multitude of devices.
For development teams eager to take advantage of these advancements, the Google AI Edge Portal is currently accessible in a private preview phase for selected Google Cloud customers. Engaging with these features could fundamentally change how generative AI applications are developed and optimized, ensuring better user experiences across diverse hardware configurations.
In an age where real-time responsiveness and efficient resource management are pivotal, Google's initiative to arm developers with these advanced tools positions them to meet the growing expectations of users effectively. If you're navigating AI application development, now may be the time to explore how these enhancements can be leveraged for your LLM projects.


